Final Project: Fundamentals of Data Science
The final project for Fundamentals of Data Science consisted of locating, cleaning, analyzing, and tuning several machine learning models on a self-selected data set. This was a solo project and represented a first attempt at applying machine learning models to robust, messy data sets.
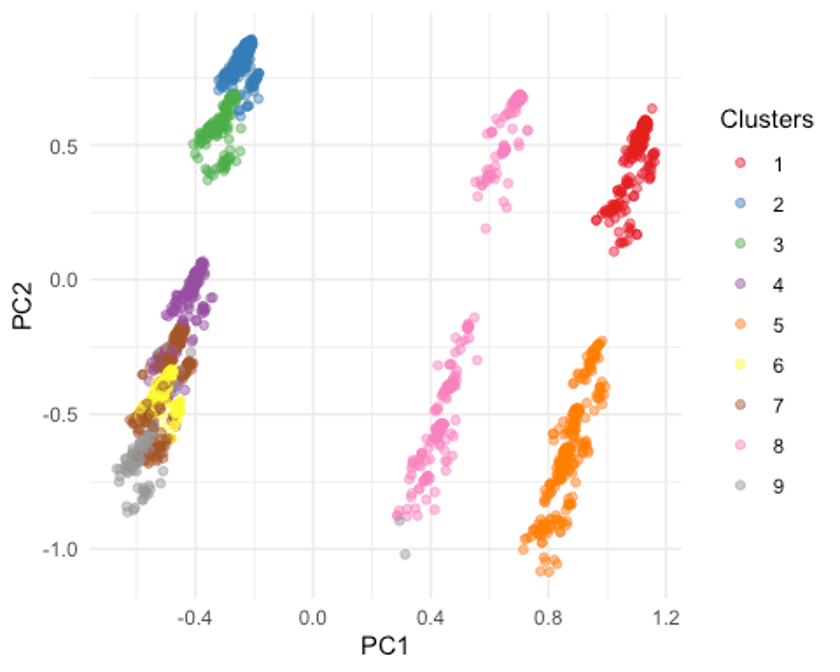
I used the Customer Personality Analysis data set from Kaggle, a selection of 2200 records from a customer survey. I chose to use k-means clustering to find underlying characteristics in customers and both an SVM and decision tree classifier to assign customers to the “catalog purchasers” category (or not; both algorithms used binary classification).
This dataset also provided ample opportunity to clean and pre-process data before tuning algorithms: the survey featured several free-text categorical responses (with many answers nonsensical) as well as numerical outliers from customers declining to meaningfully answer required survey questions (e.g. an income of $666,666). I also condensed several variables into composites and extracted relevant date information.
Since this was a first foray into machine learning techniques, the algorithms deployed are rudimentary. For example, the clustering finds 9 clusters, six of which have significant overlap, does not explore underlying trends further, and fails to name the clusters. The classifiers provided an interesting way to compare and contrast models that seek to answer the same business question and also provided hands-on practice with validation techniques, such as stratified cross-validation.
Technology
R, tidyverse, caret, factoextra, rpart, rattle
Time Spent
9 hours
Algorithms
k-means clustering, PCA, SVM, decision tree
Date Completed
November 2022
Check out the code for this project
Read the accompanying paper for this project
