Final Project: Advanced Data Analytics
The final project for this course was to work with a group and one large data set to complete at least four distinct analyses. Our group chose to work with the Behavioral Risk Factor Surveillance System dataset from 2015. Conducted by the Centers for Disease Control, this annual phone-based survey touches 40,000 US adults annually on over 300 indicators of preventative health behaviors and risks for chronic disease. The 2015 dataset was accessed through Kaggle.
Though the group worked on the final paper and presentation as a team, the analyses were individual. My role on the team was to clean the full dataset, clean the dataset for my own purposes, and conduct my analysis. I also wrote the literature review and edited the final paper. All code and observations for the project discussed here are solely my own.
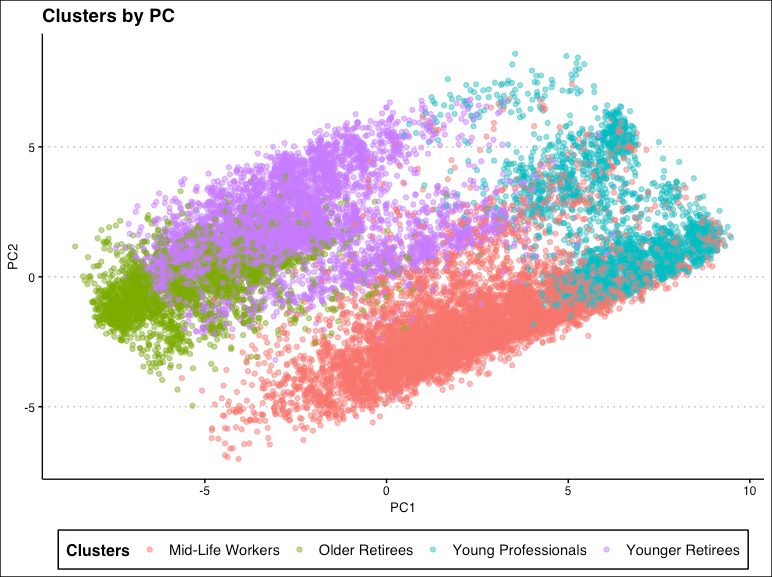
My research question sought to answer what clusters of behavior women exhibited around women’s preventative health. I filtered the data set to include only women who had answered questions about having an HPV test or PAP smear in the past, some 21,000 observations. I chose a subset of variables that pertained to women’s health and general health behaviors. Because the survey data contained a variety of scales for responses, I scaled my variables either through min-max normalization, z-scores, or decimal scaling, depending on the individual characteristics of the variable, and either eliminated null values or entered mean scores where null values existed.
I tuned a hierarchical agglomerative clustering model on both distance (binary, Manhattan, Euclidean) and linkage (complete, median, and Ward-D) before settling on a Euclidean distance with Ward-D linkage as the best model. I also experimented with cluster numbers between 4 and 7; 4 was chosen as the optimal number.
Finally, I analyzed density distribution for key variables among all four clusters and determined age and working status drove most of the separation between clusters. Therefore, the clusters are named Younger Retirees, Mid-Life Workers, Older Retirees, and Young Professionals.
Technology
R, tidyverse, caret, factoextra
Time Spent
37 hours
Algorithms
hierarchical agglomerative clustering, principal component analysis
Date Completed
August 2023
Check out the code for this project
